注:此文为我个人的胡思乱想,并没有严谨的学术论文进行佐证
Memory is all you need
使用这个副标题是借用 transformer 论文中的 “Attention is all you need”,虽然记忆不是神经网络中的必要的部分,却是进行序列处理时的必要的部分
没有记忆,神经网络便没有能力处理序列问题
而序列的处理是当前很多现实问题或者稍微复杂的问题中无法避免的
再聪明的头脑和性能再好的计算机,如果没有记忆,则一无是处
记忆
中文中记忆非常形象化的描述了这个过程,即
先记,然后忆
记是一个输入信息 (x) 的过程,忆是一个结合这部分信息 (x) 进行输出的过程,两者的物理上的关联便是这部分信息 (x),“然后” 又说明了他们在时间纬度上的先后顺序
因此我们此处所讨论的记忆,一定是存在先后顺序的序列上的时序问题,而非普通的关联
这很重要,因为由特征作为输入的普通的神经网络单元之间亦有不同程度的关联,但这并不是记忆
电脑存储和神经网络的记忆
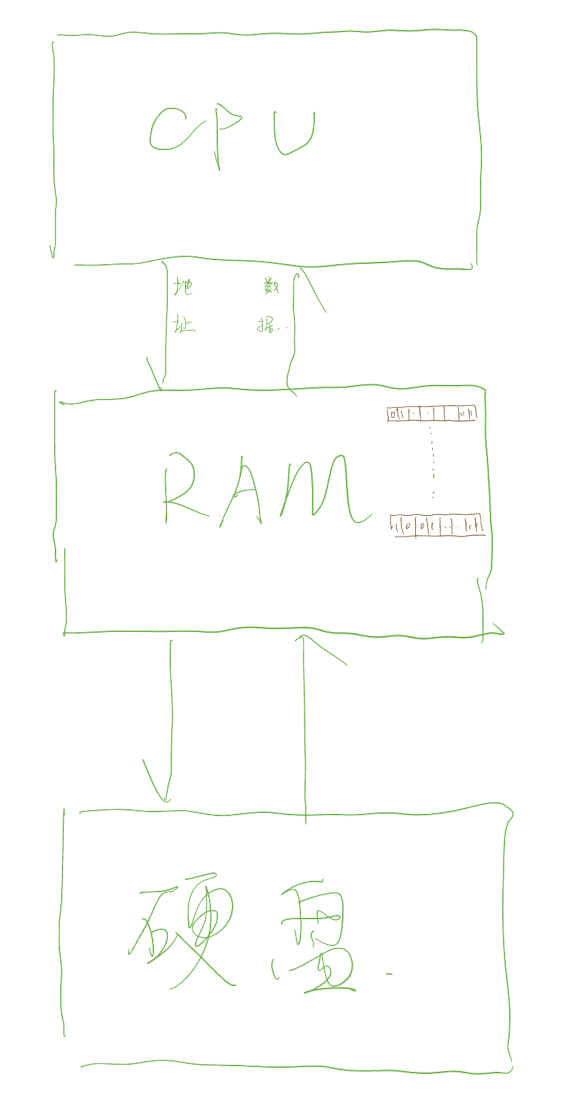
电脑存储
信息储存在固定的位置,CPU 按照 地址-数据 映射关系进行存取
人脑的记忆
显然,大脑的记忆结构与计算机的存储方式是不同的,大脑中不存在一个区域用来将信息以某种方式固定下来,等待需要的时候按需访问
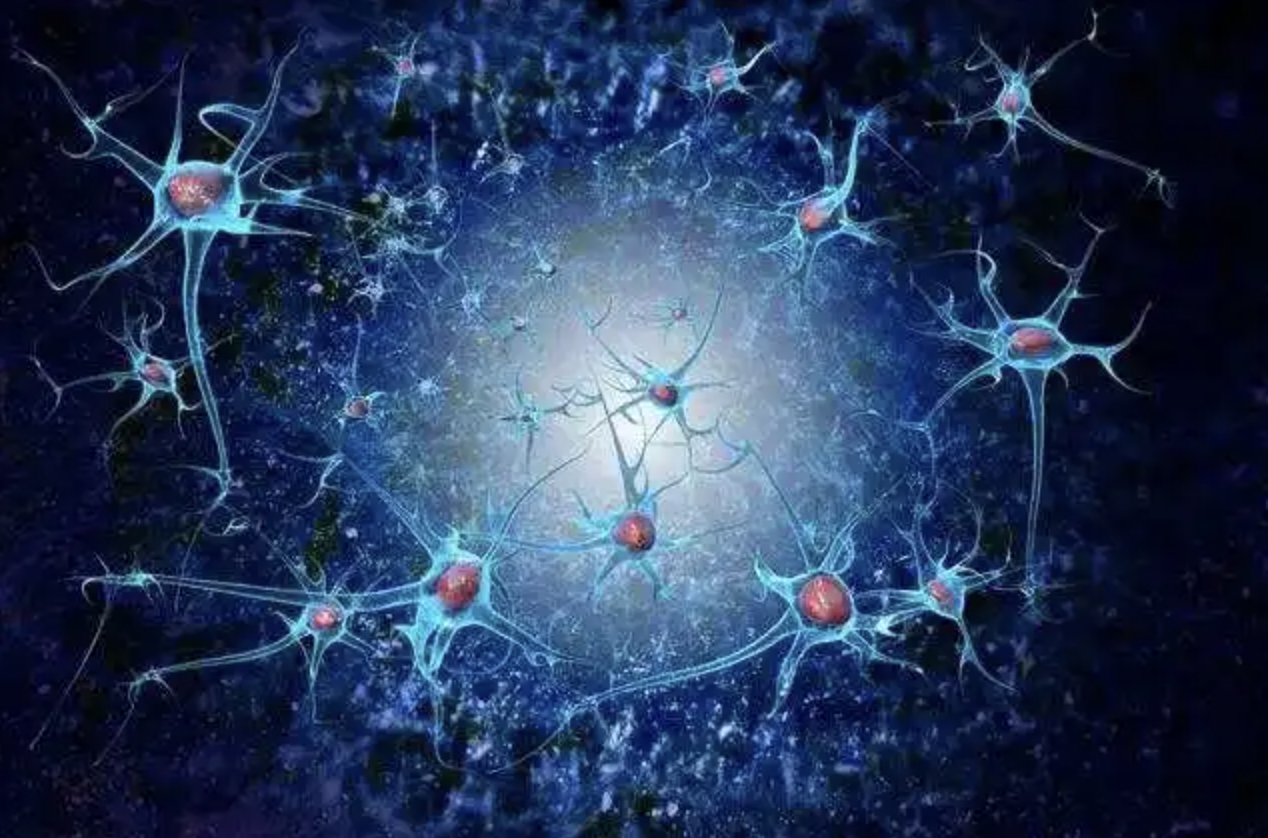
整个大脑皮层是由几十万亿的神经元链接成的神经网络
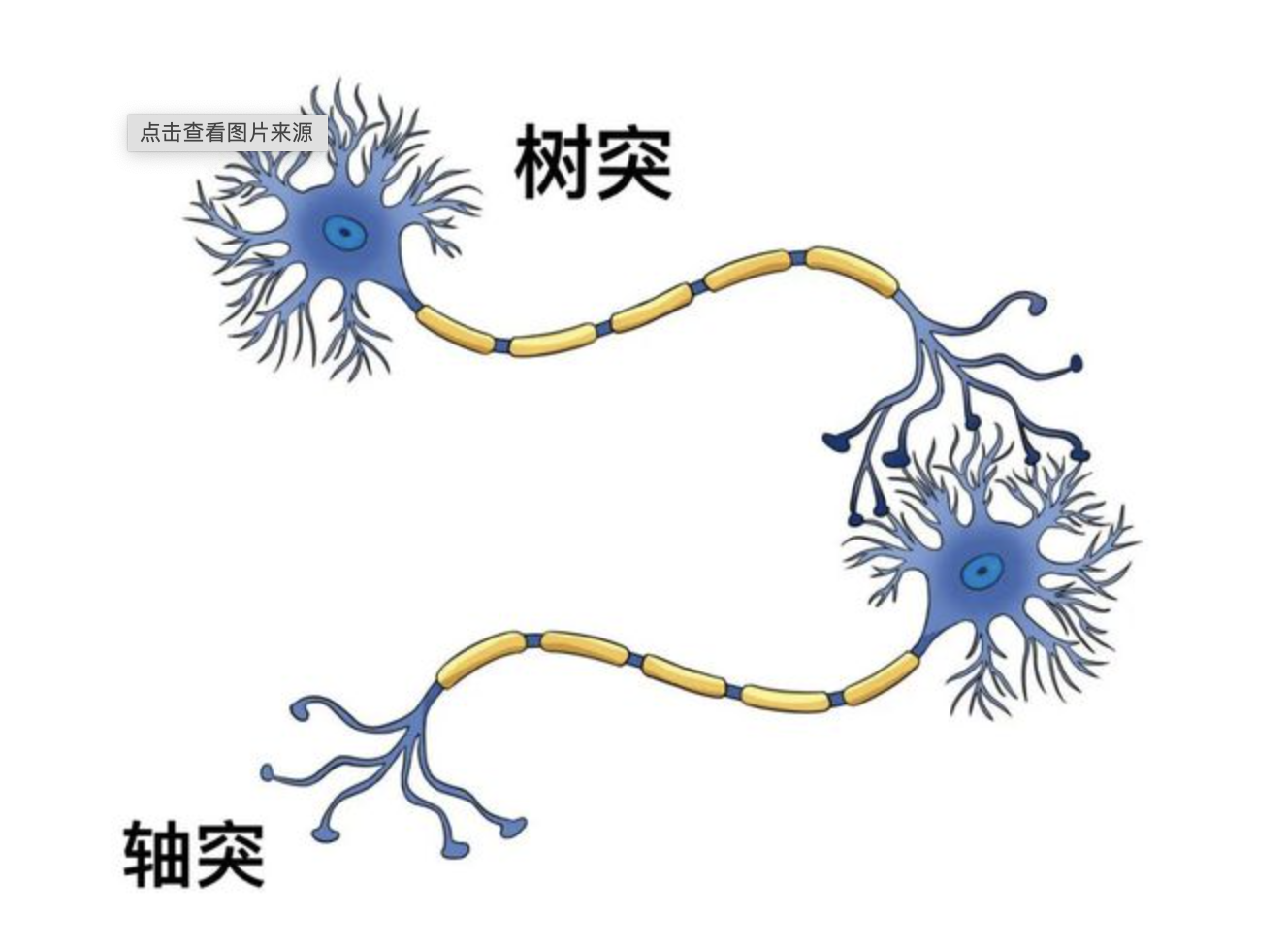
放大来看是树突加轴突组成,中间传导的是生物电流
神经网络中的记忆
人工神经元
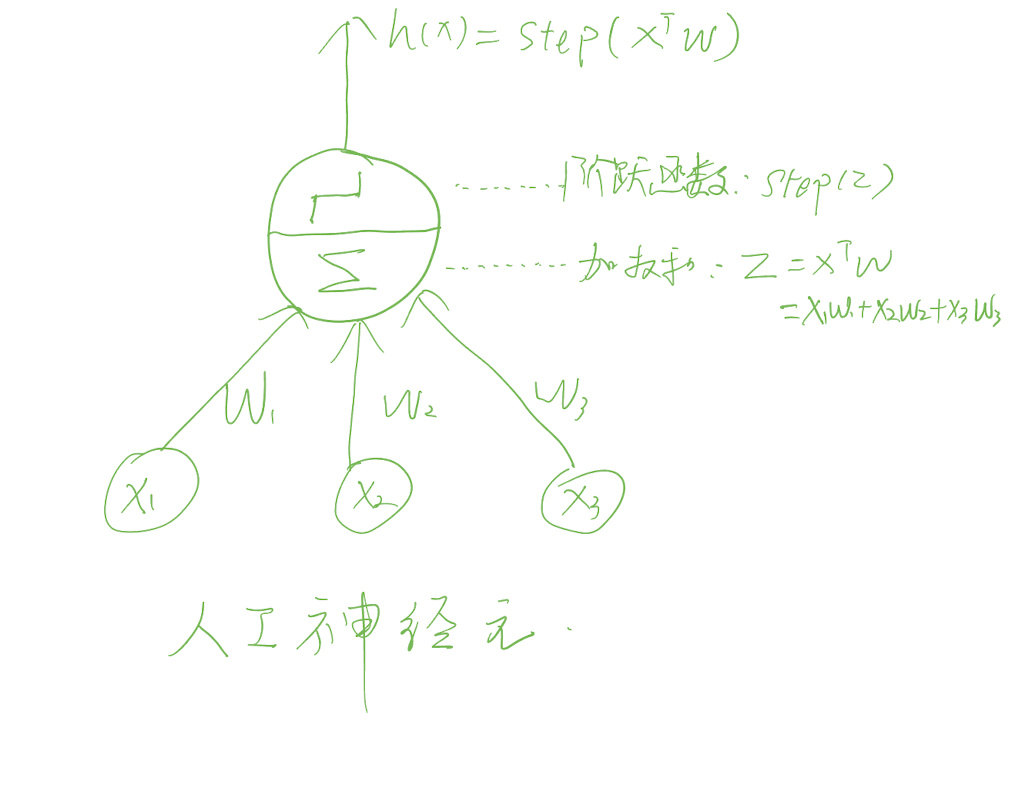
神经网络
由多个神经元组成的网络,即为神经网络
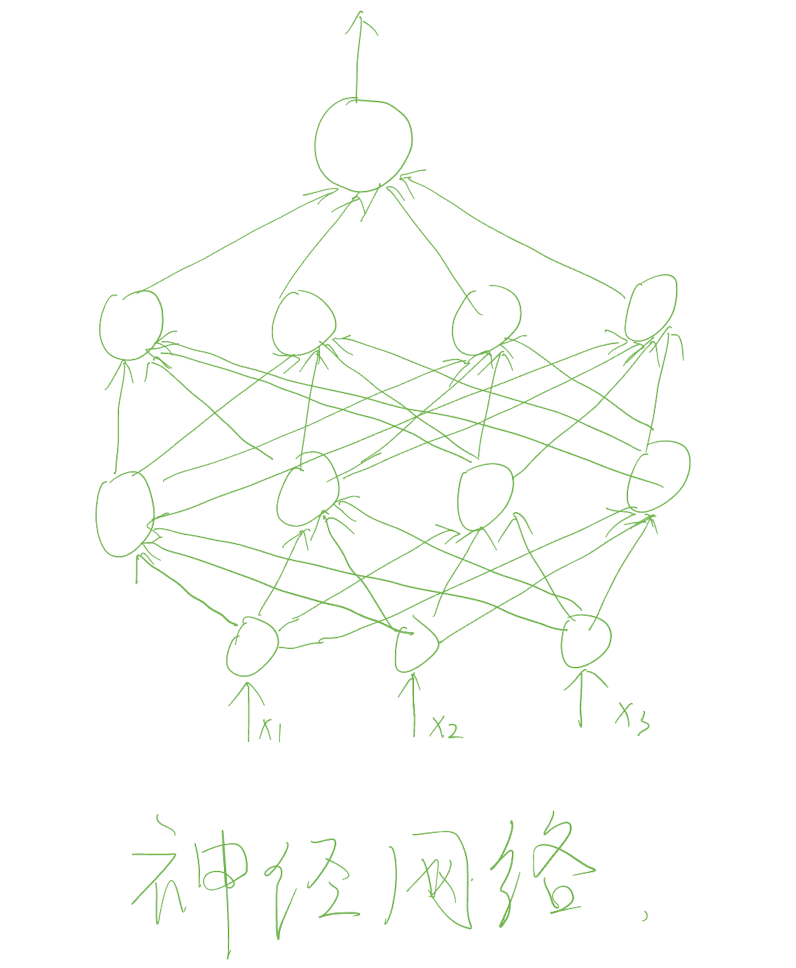
我们可以根据上述的简单的神经网络假定一种适合的任务:
给定一个单词,判断这个单词是否是敏感词
传入层传入的是单词经过处理后的表征向量,输出布尔类型
RNN
普通的前馈神经网络,其中激活仅在一个方向上流动,从输入层流向输出层
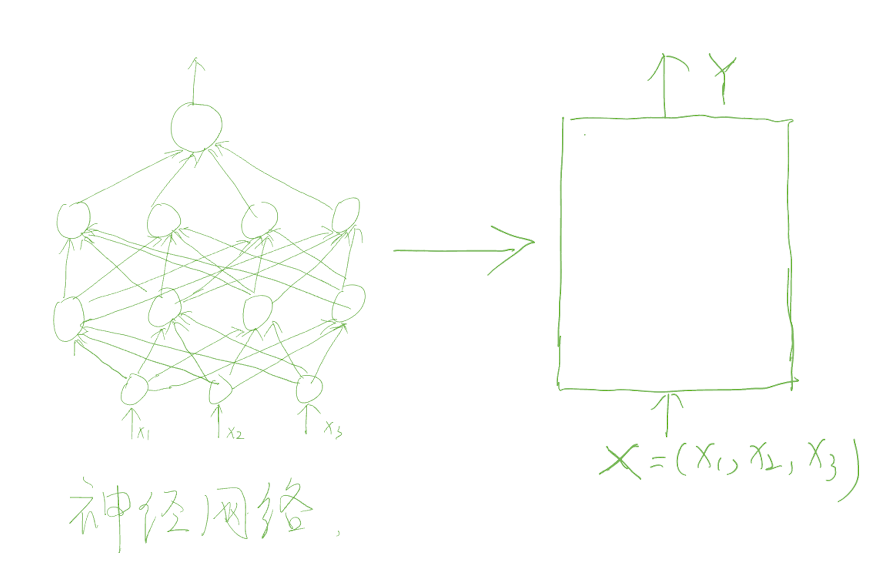
普通前馈神经网络的局限
普通前馈神经网络只能处理独立的输入数据,而时序数据具有依赖关系,即当前时刻的输出依赖于之前时刻的输出。例如,在自然语言处理中,一个句子的语义不仅取决于当前词的含义,还取决于之前词的含义
例如,英语单词 “can” 可以翻译成 “可以”、“罐子”、“能够” 等多个意思。如果没有上下文关联,机器翻译无法确定哪个翻译是正确的。在普通前馈神经网络中,“I can open the can” 可能会被翻译成 “我 可以 打开 这个 可以”
普通的前馈神经网络因为没有记忆,无法有效的利用前后时序信息,导致在某些时序任务上无法实现理想的效果
RNN 的记忆机制
RNN 则通过记忆之前时刻的信息来解决时序依赖问题。具体来说,RNN 在每个时间步都会将前一个时间步的隐藏状态作为输入,与当前时间步的输入一起计算当前时间步的输出和隐藏状态
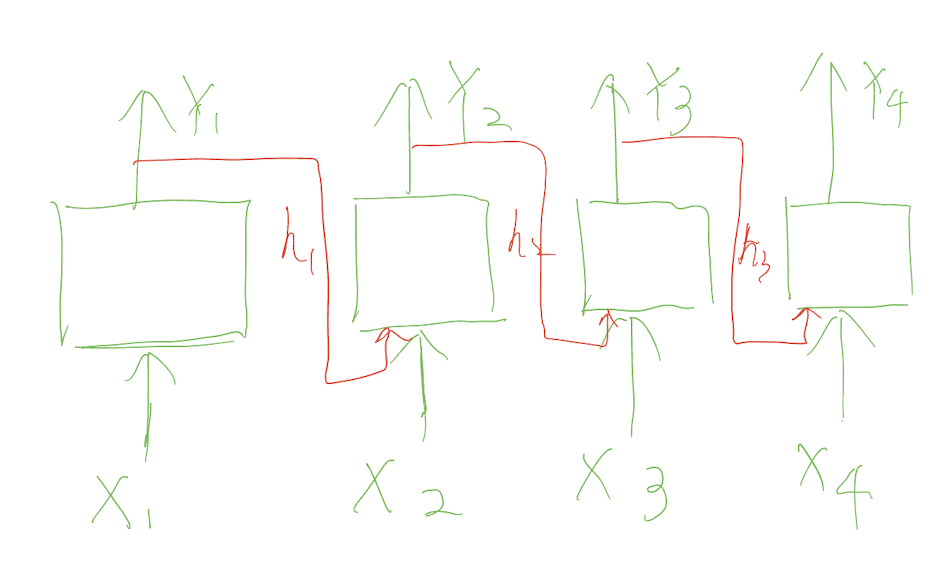
RNN 可以解决的其他问题包括:
- 语音识别
- 手写体识别
- 时间序列预测
LSTM & GRU
由于数据在遍历 RNN 时会经过转换,因此在每个时间步长都会丢失一些信息。一段时间后,RNN 的状态几乎没有任何最初输入的痕迹
另外,RNN 容易出现梯度消失和梯度爆炸问题,这使得 RNN 在训练时很难收敛。为了解决这些问题,人们提出了长短时记忆网络 (LSTM) 和门控循环单元 (GRU) 等改进型 RNN
LSTM 的核心思想
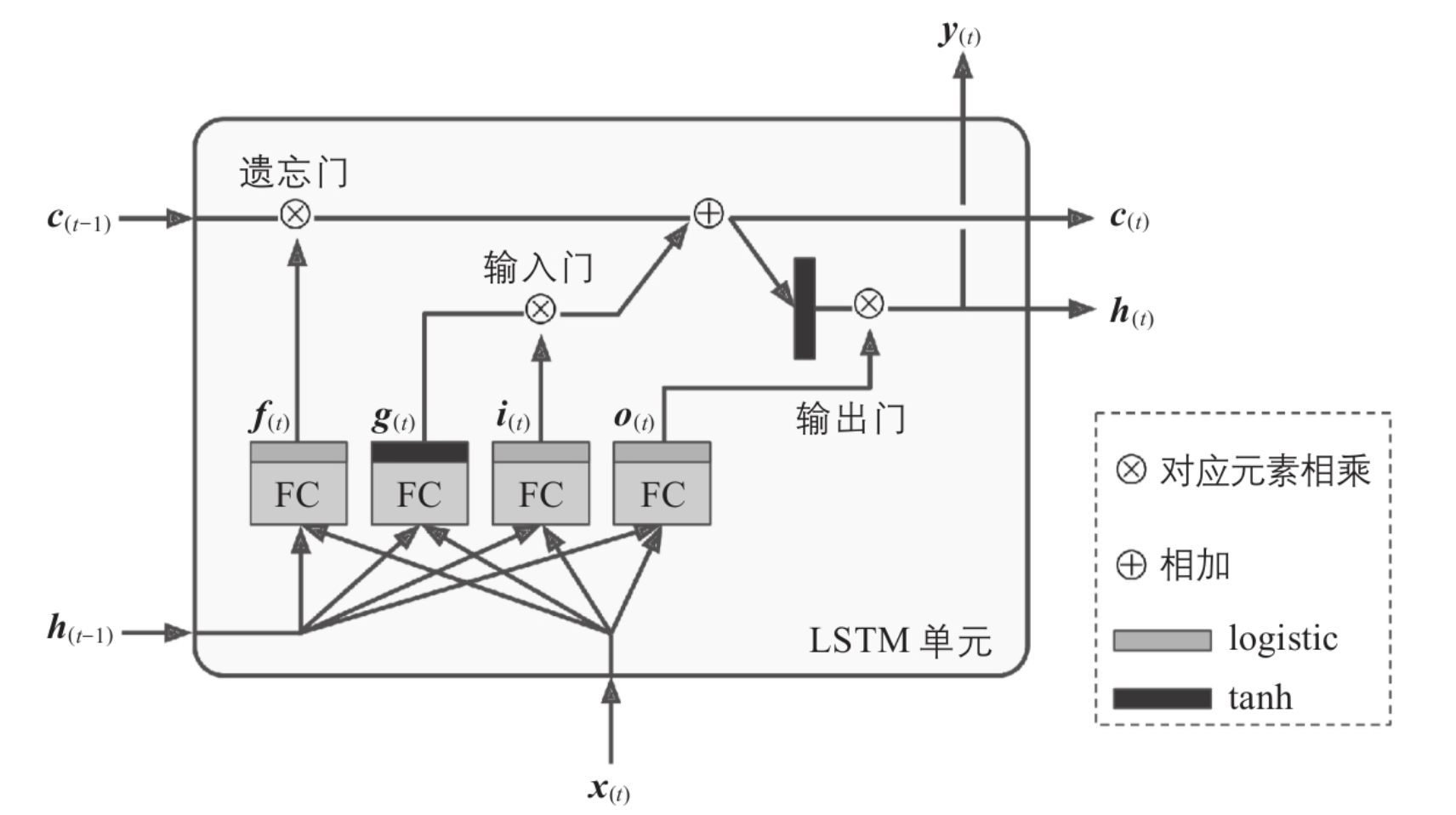
LSTM 新增一个 C(t) 来传递长期记忆,C(t) 流过每个 LSTM 单元时,删除一点不重要的记忆,然后新增一些该单元认为重要的记忆。这样的单元叫做长短期记忆单元
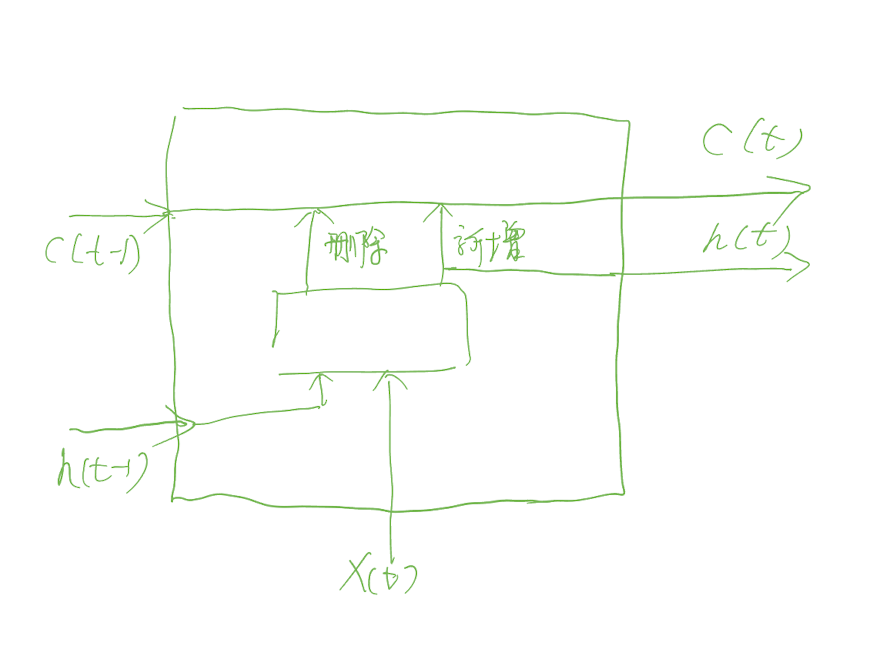
使用 LSTM 构成的网络可以解决记忆的丢失问题,也可以有效地解决梯度消失和梯度爆炸问题
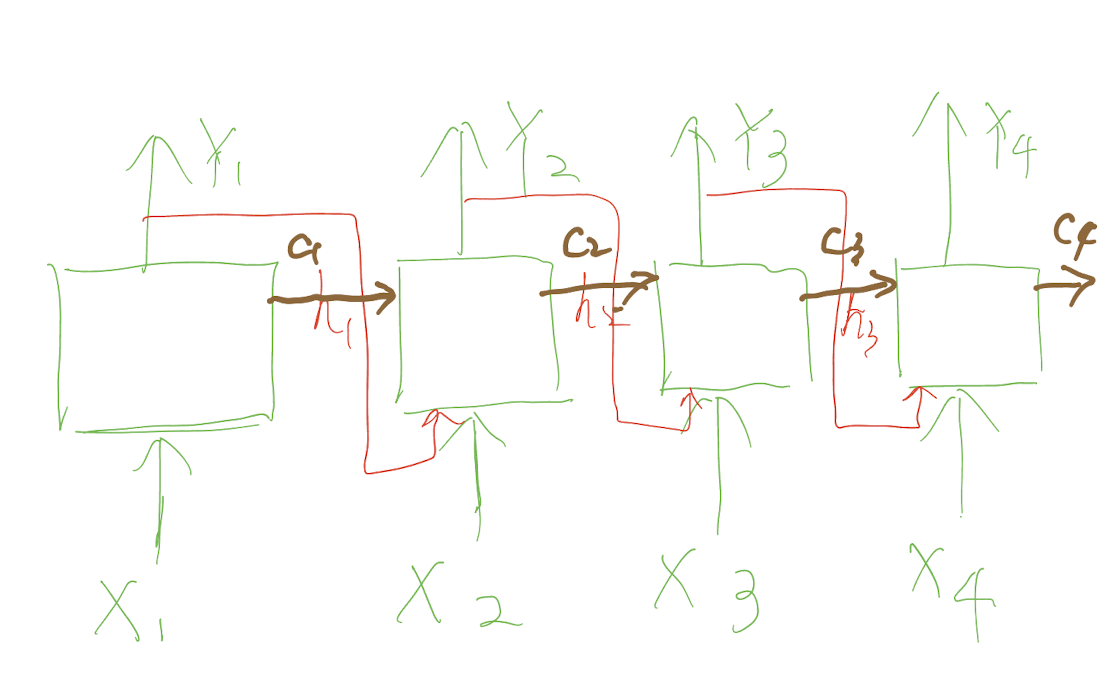
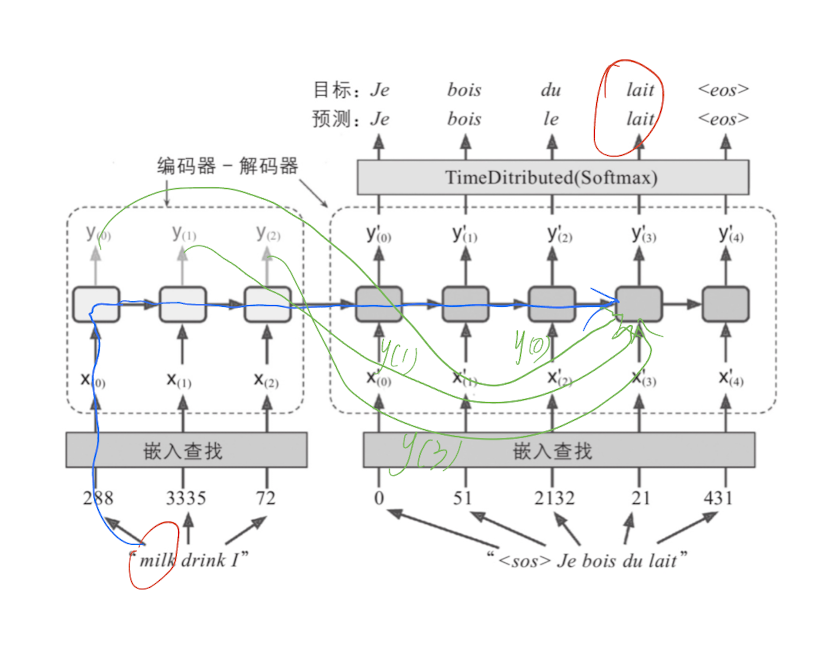
编码器-解码器网络 (Encoder-Decoder)
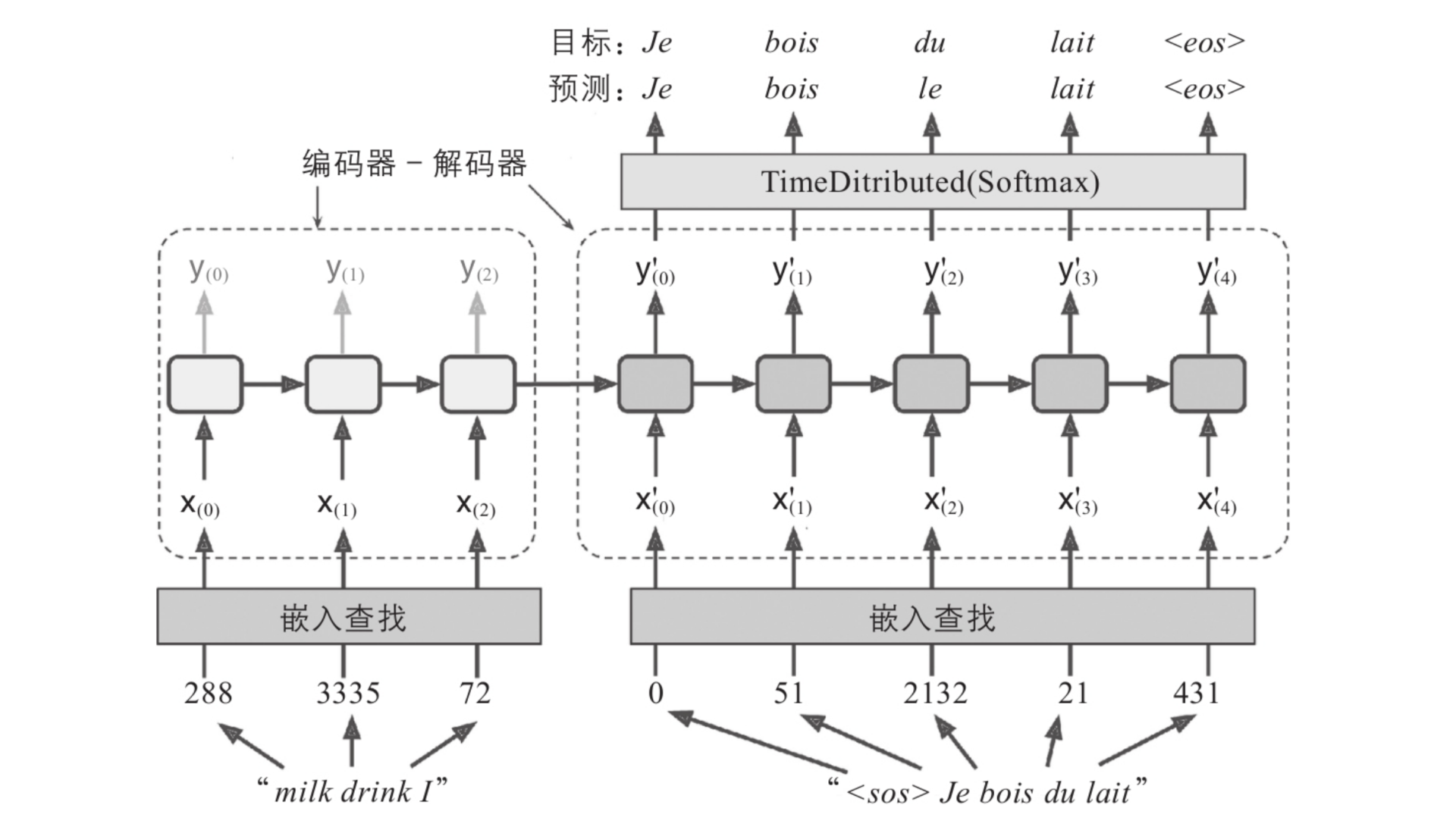
编码器-解码器网络是一种用于解决时序问题的深度学习模型。它由两个部分组成:编码器和解码器。编码器负责将输入序列编码成一个向量表示,解码器则负责将该向量表示解码成输出序列
在编码器-解码器网络中,记忆机制是解决时序问题的重要手段。记忆机制可以帮助模型记住输入序列中的信息,并在解码时使用这些信息生成输出序列
注意力机制
为什么需要注意力
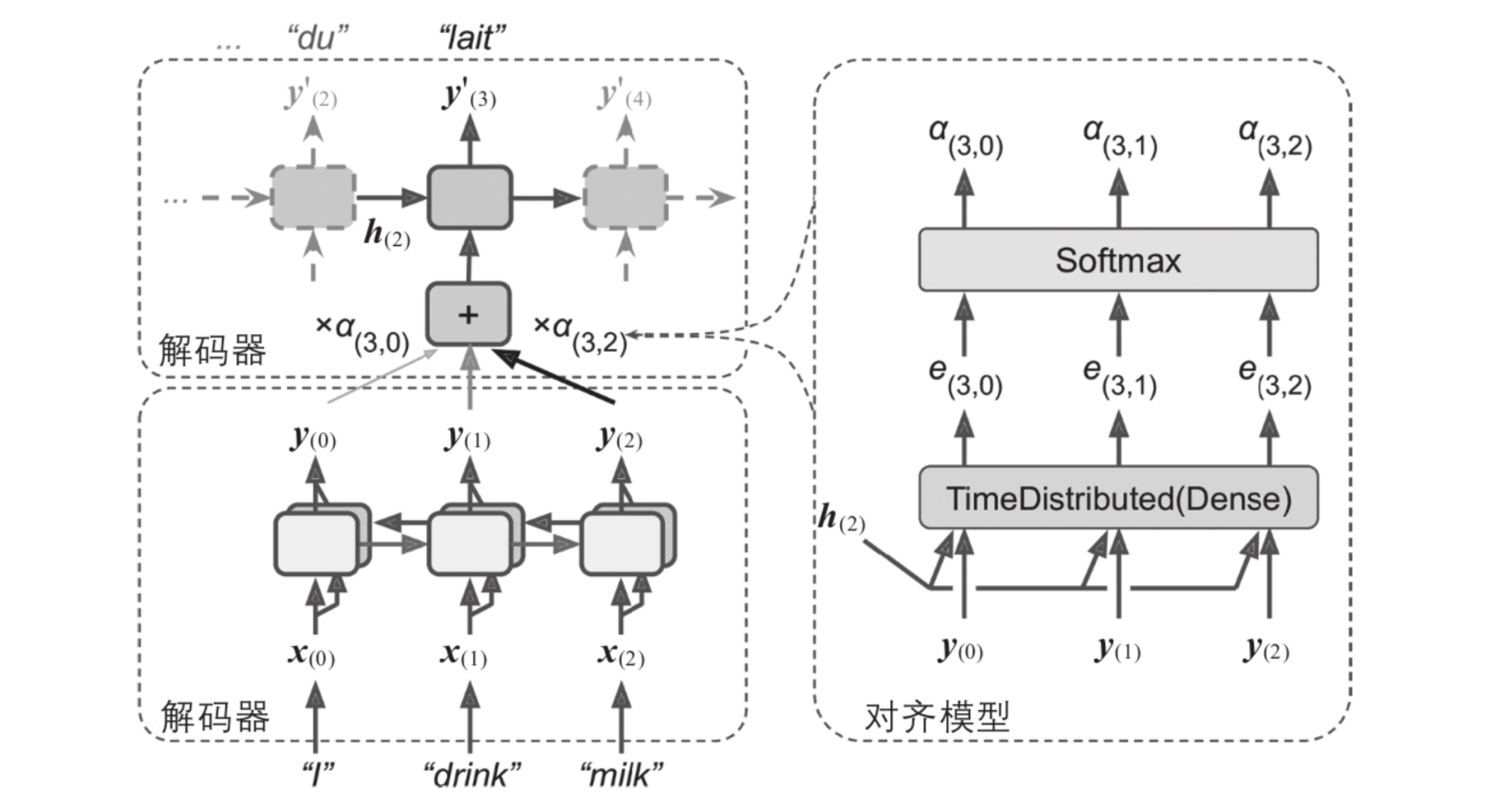
从单词 “milk” 到其翻译 “lait” 的路径:它非常长!这意味着这个单词的表征在实际使用之前需要进行许多步骤
C(t) 这个长期记忆经过不断的删减,保留到现在,当我当前作出决定时依赖这个 C(t) 是过去所有时间所有记忆的综合结果,我们无法得知和过去具体的哪个事件有关联,这样的记忆传导方式可能会导致传递的信息失去准确性,并带来了不可解释性
Transformer
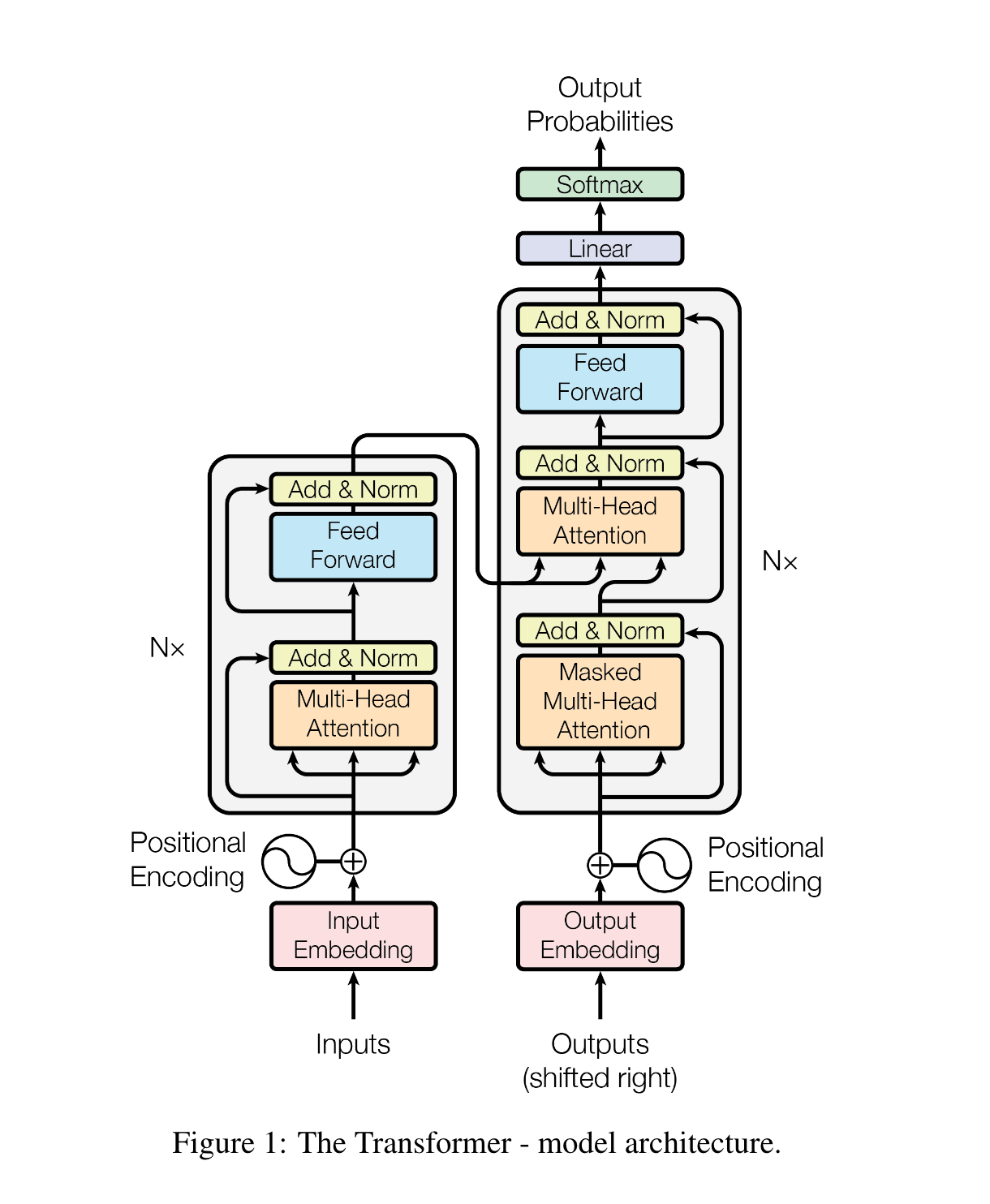
左侧是 Encoder,右侧是 Decoder
Transformer 中的记忆的流动,关注三个点:
- Encoder 和 Decoder 自身中记忆如何关联和传递
- Encoder 记忆和 Decoder 的记忆如何交互
整个 Transformer 的输入是 Inputs,假设我们以一个机器翻译(英译中)的任务为例的话,inputs 就是英文中的一句话
经过 Embedding 嵌入得到一个词向量的矩阵


Attention
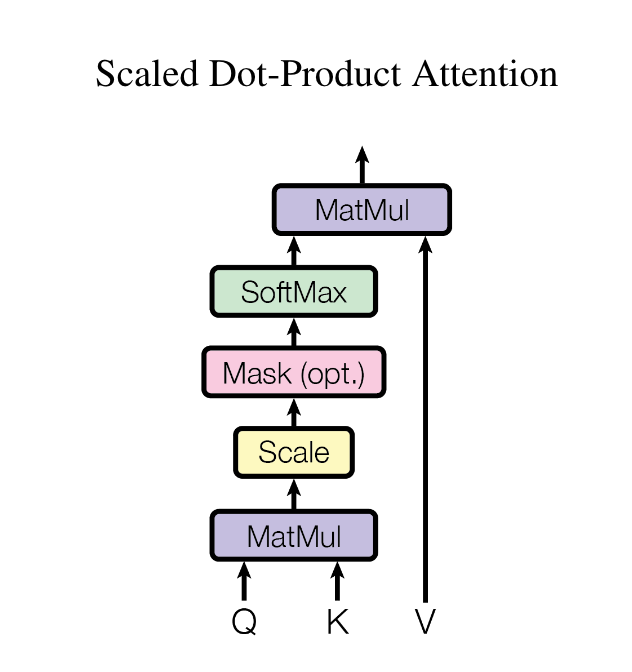
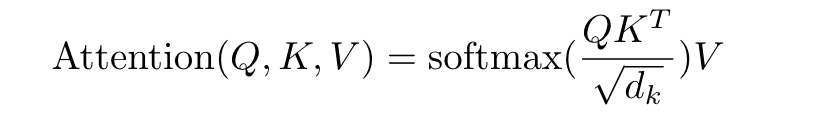
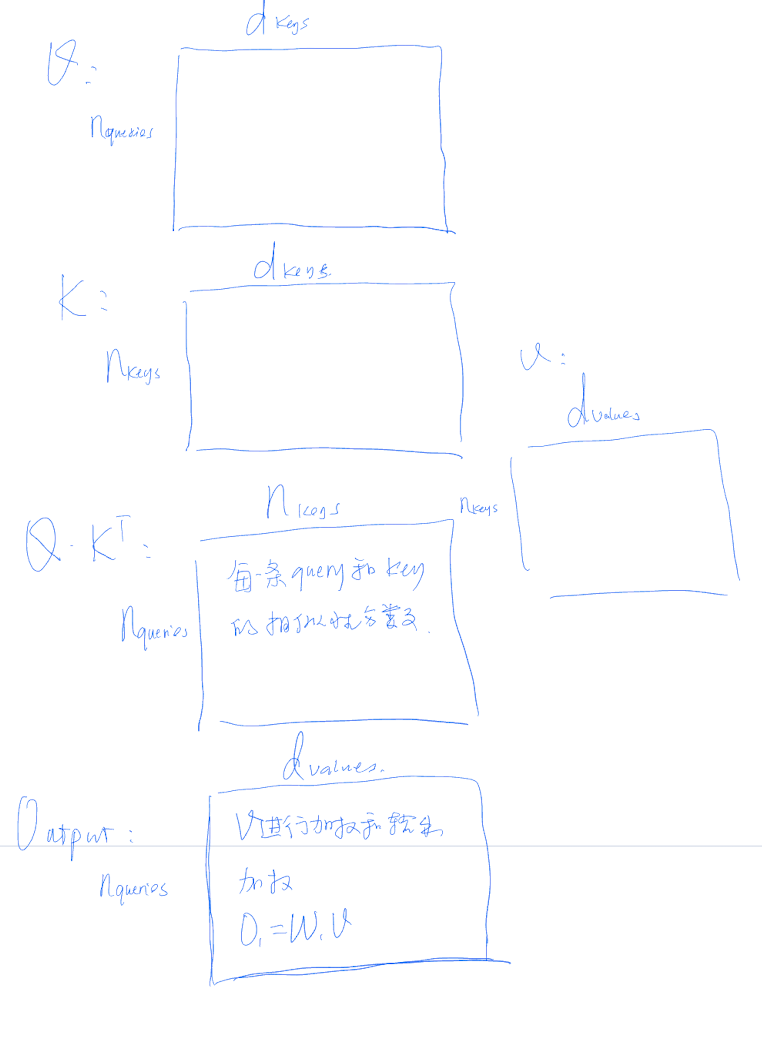
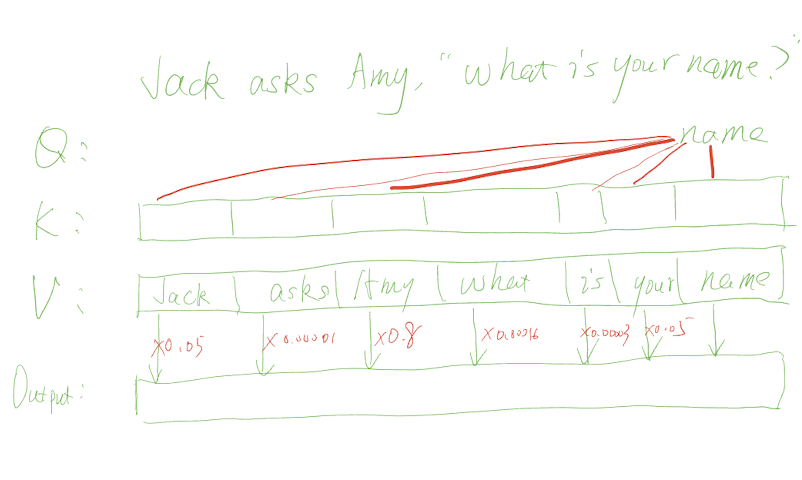
Self-Attention
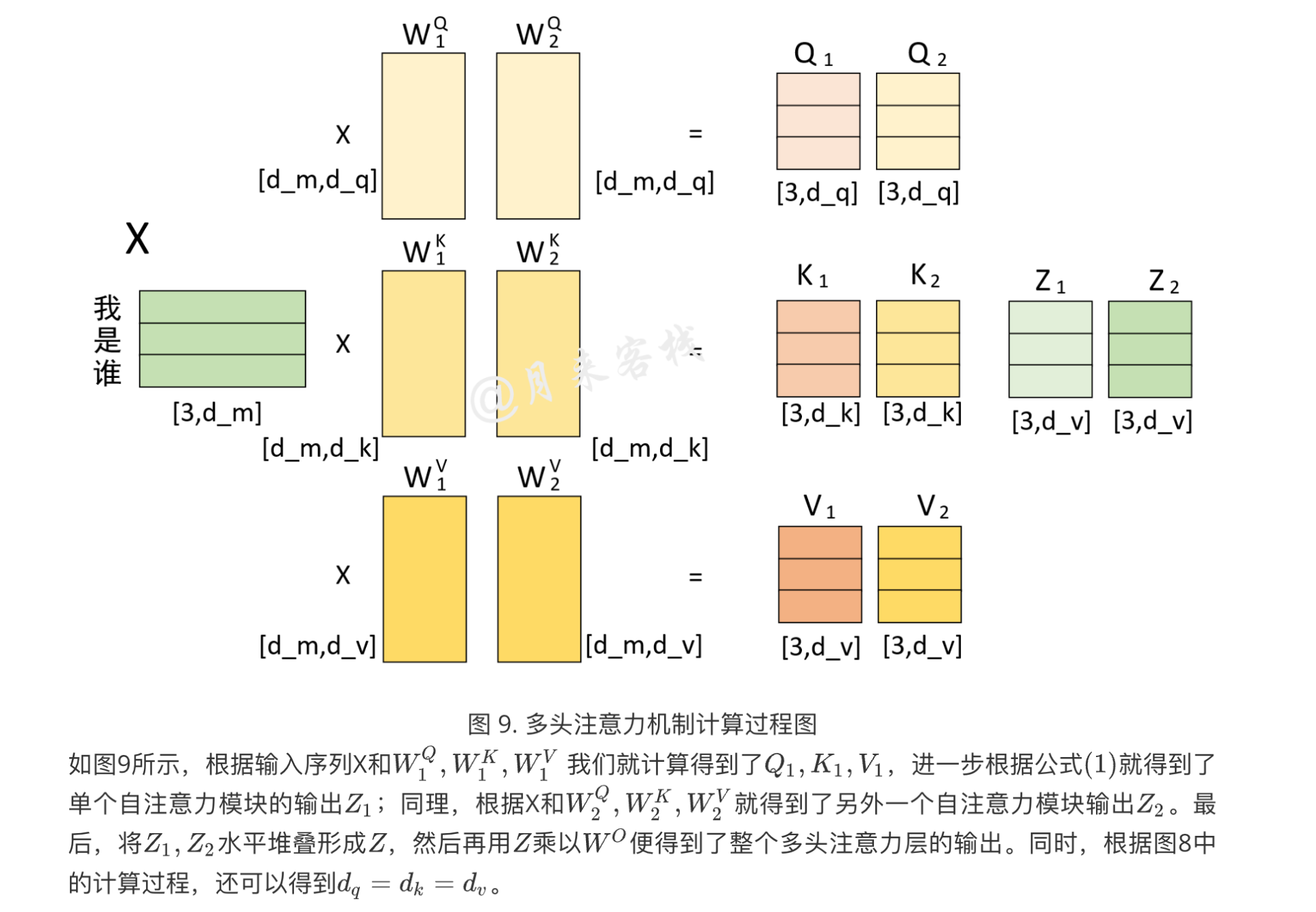
Multi-Head Attention
模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,因此作者提出了通过多头注意力机制来解决这一问题。同时,使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力
在传统的注意力机制中,模型通过计算查询(query)、键(key)和值(value)之间的关系来生成输出。而在多头注意力中,这个过程被扩展为多个并行的注意力层,每个层都有自己的查询、键和值。这些层被称为"头"(heads),每个头可以关注序列中不同位置的信息,并且可以学习到序列的不同方面的表示。
多头注意力的工作原理如下:
- 线性投影:首先,输入的查询、键和值通过不同的、学习得到的线性投影被转换到不同的表示空间,这些空间的维度通常较小,例如原始维度的 1/h,其中 h 是头的数量。
- 并行注意力计算:每个头独立地应用标准的注意力机制(例如缩放点积注意力)来计算输出值。
- 输出拼接:所有头的输出值被拼接在一起,并通过另一个线性投影生成最终的输出。
多头注意力的优势在于它能够同时捕捉序列中不同位置的多种依赖关系,而不是像单头注意力那样只能捕捉到一种依赖关系。这使得模型能够更好地理解复杂的序列数据,并提高其在各种序列处理任务上的性能
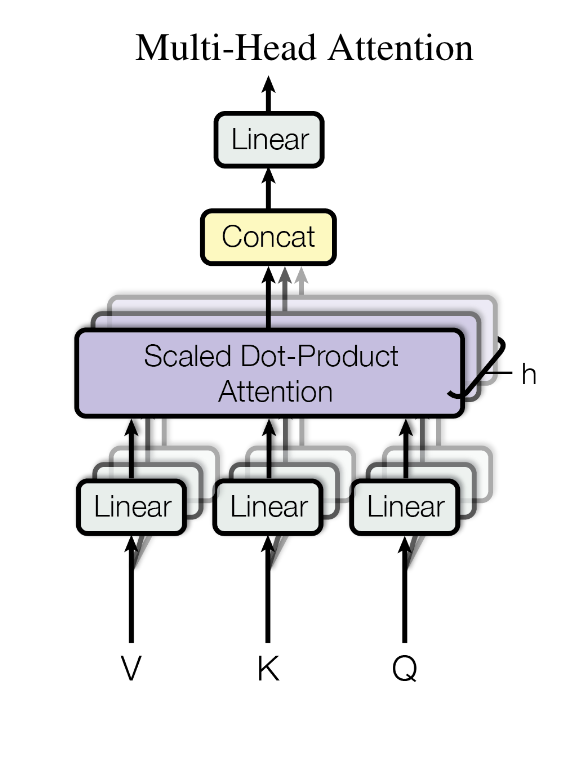

多头注意力机制其实就是将一个大的高维单头拆分成了多个头
参考
https://weread.qq.com/web/bookDetail/f6032780811e3728eg017bc2
https://weread.qq.com/web/bookDetail/c81324b0720befa3c81025e
https://weread.qq.com/web/bookDetail/e8e327a07208f4d1e8ec475
https://arxiv.org/abs/2403.18839